Multi-Doc Q&A RAG System
This project implements a production-oriented Retrieval-Augmented Generation (RAG) system that can answer questions over multiple document types such as PDFs, DOCX, TXT, Markdown files, and web URLs.

1 / 5
Deployment & Code
Project Snapshot
Core Stack
NLP
RAG
Ollama LLMs
FAISS
Docker
Streamlit
FastAPI
Python
Overview
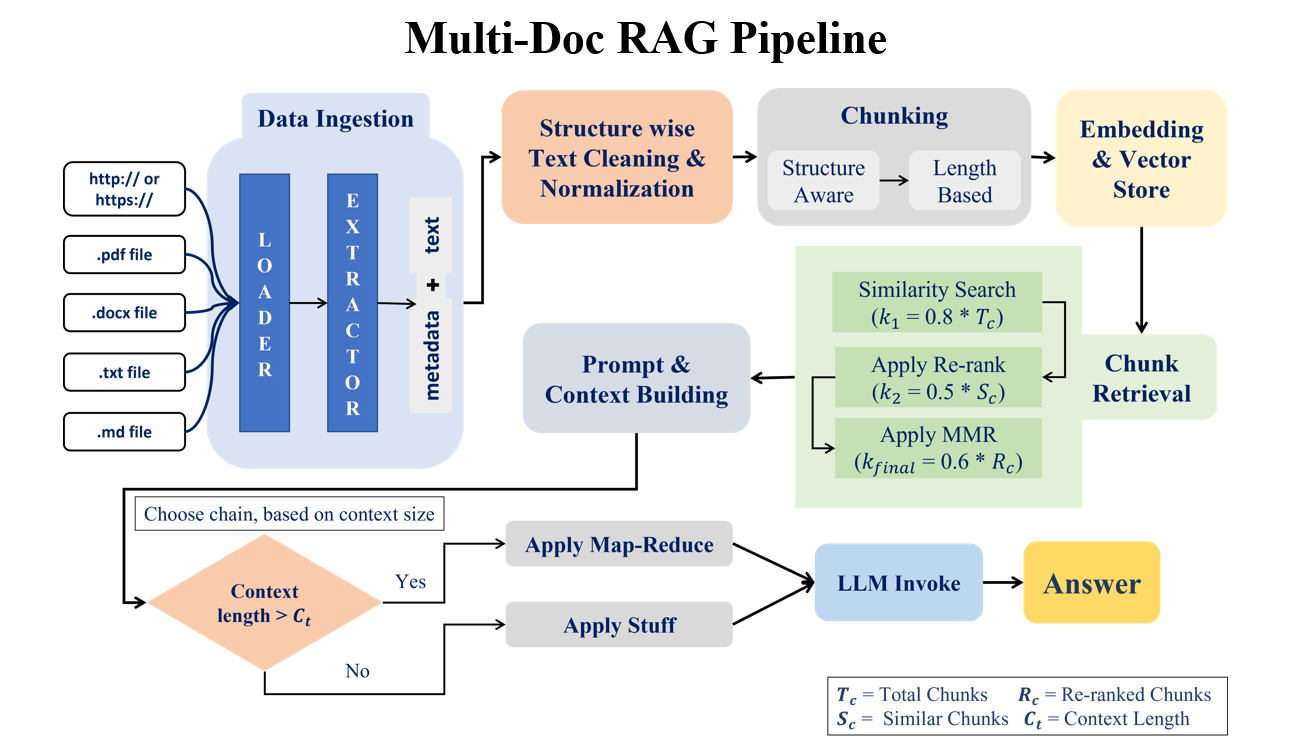
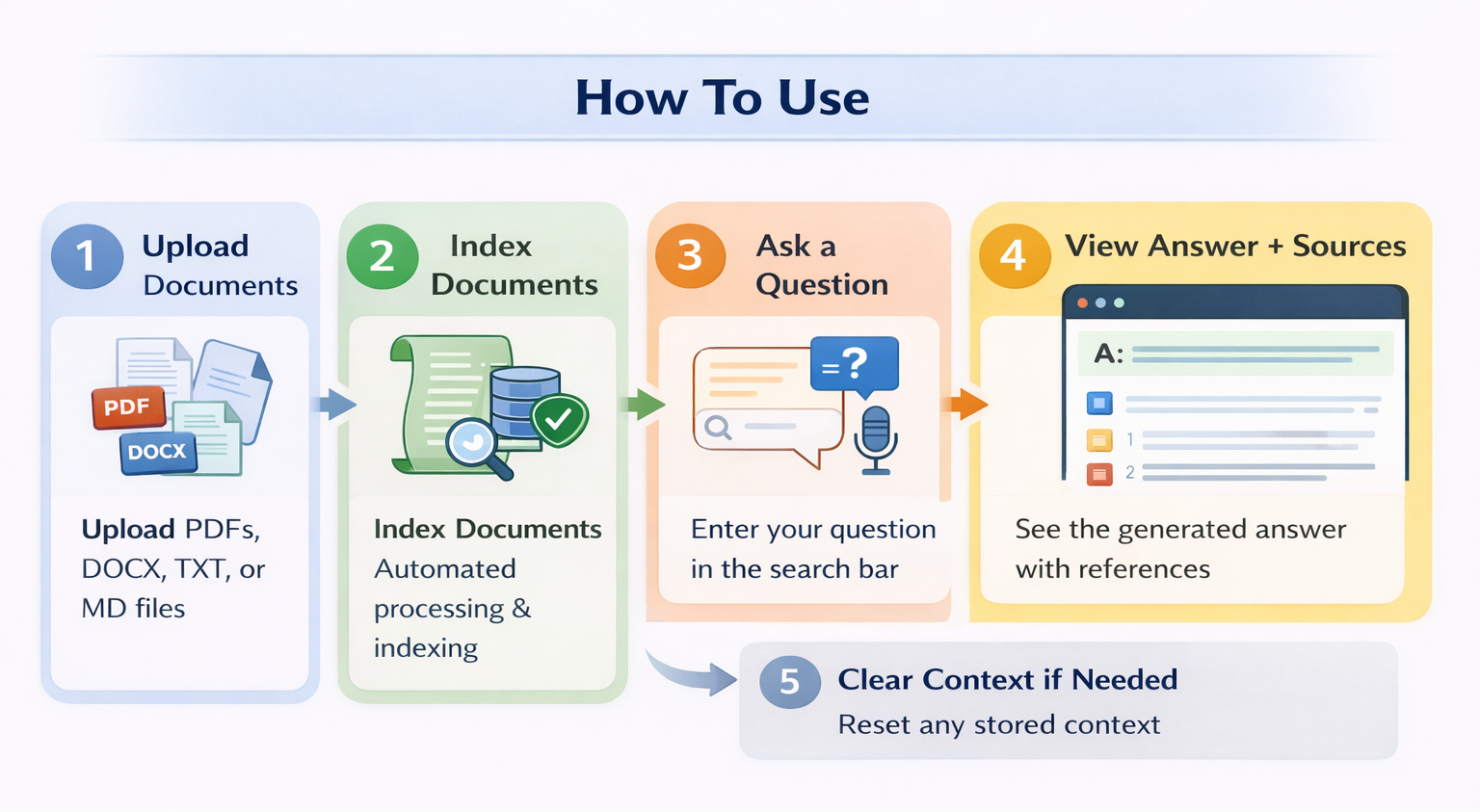
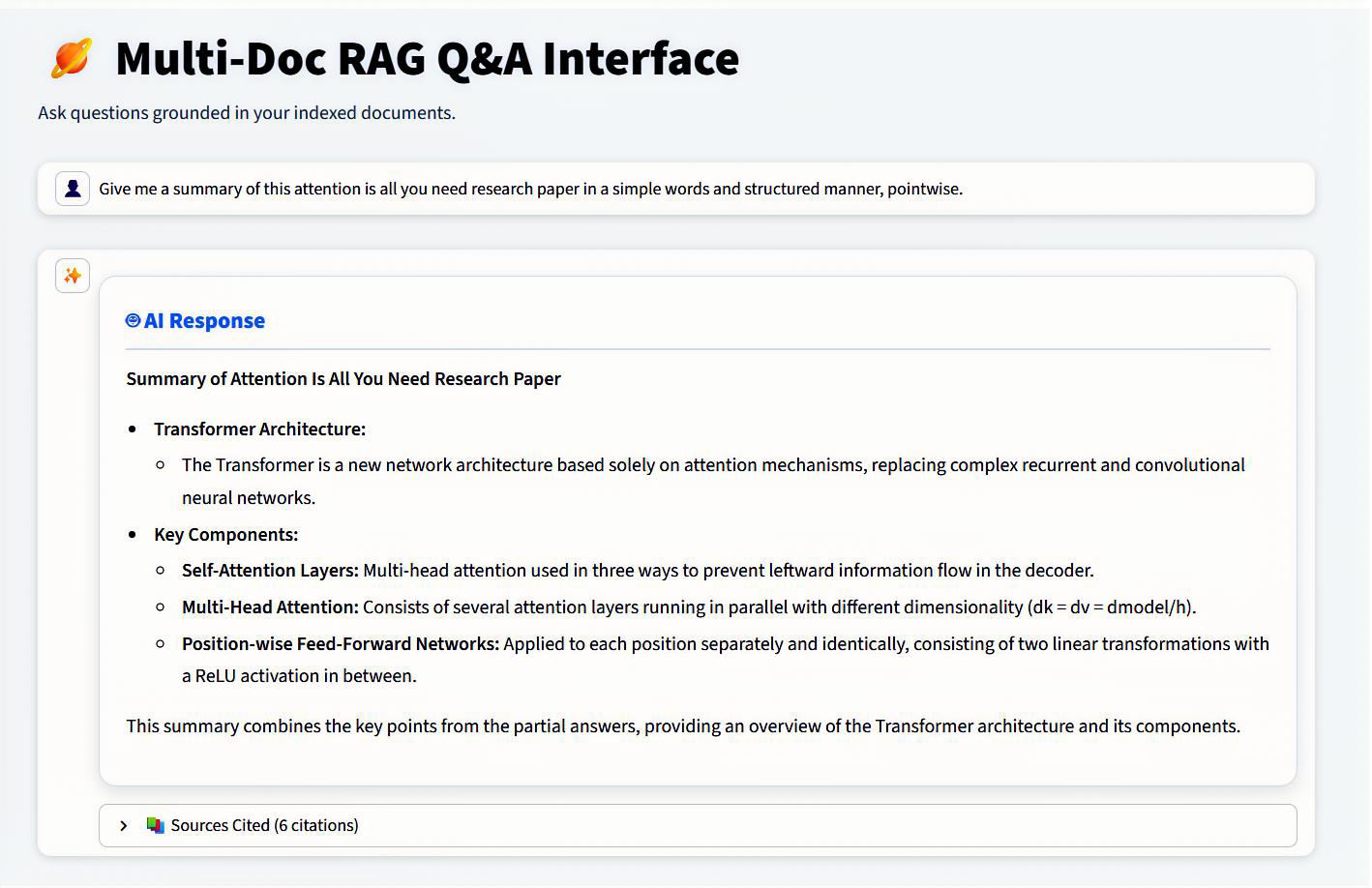
This project implements a real-world, production-ready Retrieval-Augmented Generation (RAG) question-answering system designed to efficiently answer questions from large document collections. The system first ingests documents from multiple sources such as PDFs, Word files, text files, and URLs, extracts both text and metadata, and cleans the content in a structured manner. The cleaned data is then split into meaningful chunks, converted into vector embeddings, and stored for fast retrieval. When a user asks a question, the system intelligently retrieves the most relevant document chunks using similarity search, improves accuracy through re-ranking and diversity optimization, and builds a focused context for the language model. Depending on the context size, it dynamically applies either a simple or map-reduce strategy before generating the final answer using fast, locally running LLMs. The result is a system that balances accuracy, speed, scalability, and simplicity, making it suitable for document Q&A, internal knowledge bases, research assistants, and enterprise-level document search—without relying on costly external APIs.